agentic chat over synthetic bank data
a local n8n + ollama agent that answers natural-language questions over a synthetic bank api, running on a cpu-only homelab. no vendor in the loop, ~500 transactions of synthetic data, qwen2.5:7b doing the tool-calling.
three days ago i stood up ollama and n8n on the homelab and ended the post with the honest what now? — i didn’t have a workflow yet. this is the workflow. a chat that lets me ask things like “how much did i spend on dining last month?” against fake bank data. consumer-banking ai assistant, on hardware i own.
three pieces:
- a small mock backend exposing personal-banking endpoints over http, seeded with synthetic transactions
- the n8n agent loop wired to ollama with the mock api as a tool surface
- a dashboard ui — cache & co. — that consumes the api and embeds a chat bubble pointed at the n8n webhook
build log style. i’ll walk through what i built, what bit me, and what surprised me about how the model behaves once it has tools.
why mock data
real bank apis would have been a six-week onboarding adventure for a homelab experiment. i wanted to spend the time on the agent loop — tool selection, prompt design, the chat ui — not on aisp consents. so: synthetic data, deterministic seed, six months of fake transactions in a single express service. (the general case — why a synthetic api is the substrate for agentic dev, not just a placeholder you tolerate until the real backend ships — is its own post.)
the constraint also gave me freedom. i could pick categories that made the demo readable (groceries, dining, subscriptions, salary, rent) and merchants that read as danish (netto, føtex, joe & the juice, andel energi, tdc). the bank itself i named cache & co. — pronounced “cash and co.”, classy if you don’t know what a cache is, a pun if you do. sister wordmark to scalable labs.
the mock backend
mock-bank-api, a single express + typescript service. one file for the routes, one for the seeded generator, one for date-period helpers. the generator uses a mulberry32 prng with a fixed seed so the merchant mix and amount distribution stay stable across restarts. only the date anchor moves with the system clock — last_month resolves against today.
endpoints are shaped to match the kinds of questions a consumer-banking chat assistant gets asked:
GET /accounts
GET /transactions ?period ?category ?merchant ?type
?from ?to ?min ?max ?q
GET /aggregate ?by=category|merchant|month ?period
GET /recurring
GET /statements ?year ?month ?accountIdthe deliberate move was making period accept named values (last_month, ytd, last_30_days, current_month) alongside raw from/to. lets the model say “last month” without doing date arithmetic.
seeded data lands at ~500 transactions over six months — a salary on the 25th, rent on the 1st, all the usual subscriptions (netflix, spotify, github, icloud, gym), variable groceries and coffee daily. the running balance can go negative, which is also the point — spending overview with a real-looking hole in it makes for better demo questions than a tidy spreadsheet.
with the dashboard live, the request log on the api side reads like a small banking app’s read path — the same five endpoints, fanning out the moment the page loads:
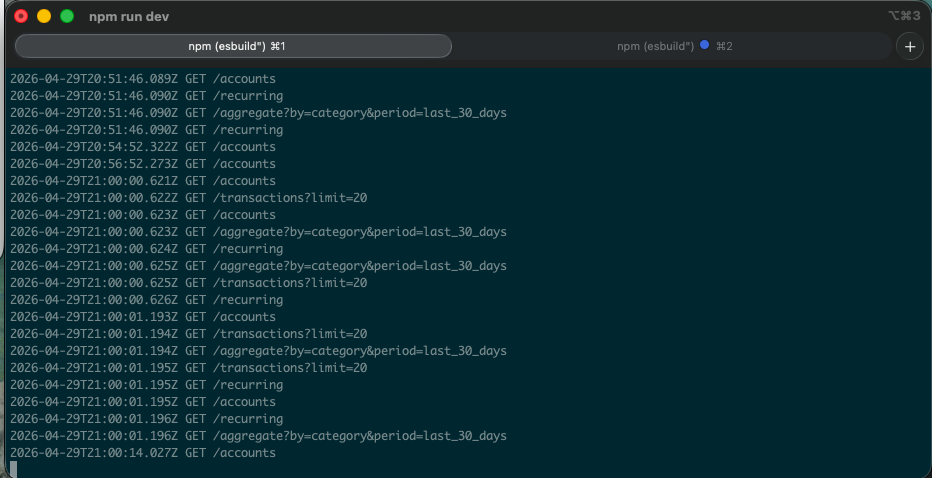
the n8n agent loop
the n8n side is a single workflow named bank chat. the topology:
chat trigger ──► AI Agent
│
├── ollama chat model (qwen2.5:7b)
├── window buffer memory (length 8)
└── 5 × http request tools
├── list_accounts
├── aggregate_spending
├── list_transactions
├── find_recurring_charges
└── get_monthly_summary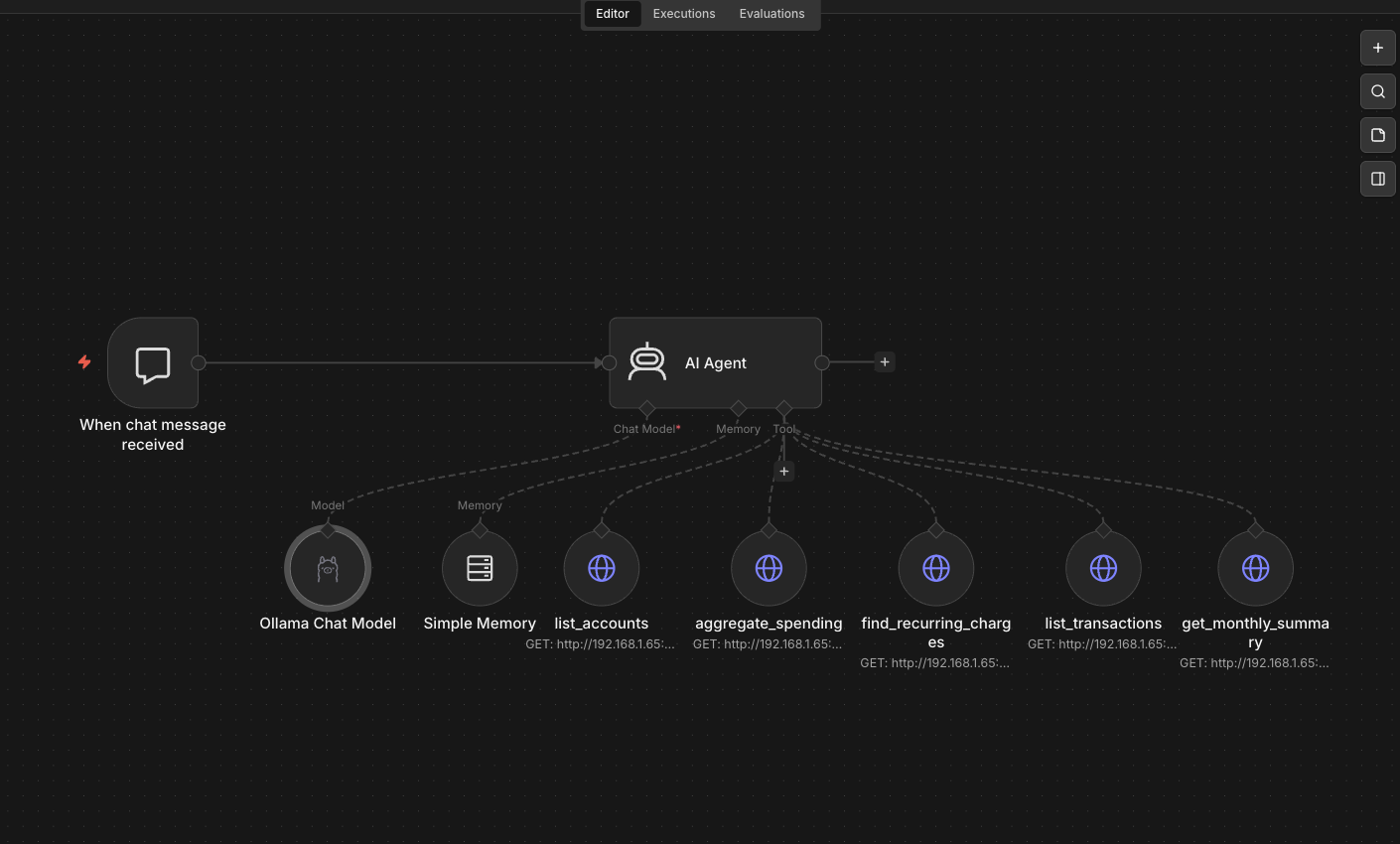
qwen2.5:7b over llama3.1:8b for the chat model — qwen returns cleaner tool-call json under n8n’s tools-agent harness in my testing. each tool is an http request node pointed at the mock api with the relevant query parameters set to “defined by the model” — n8n’s per-field $fromAI(name, description, type) mechanism. the model fills them at runtime based on the user’s question.
the description text on each tool matters more than i expected. it’s the only signal the model has when picking. early on, with a vague description for list_accounts and a not-much-better one for aggregate_spending, qwen routed “how much did i spend on dining last month?” to list_accounts and made up a balance-flavored answer instead of calling the right tool. the fix wasn’t a prompt; it was making each tool’s description start with the kinds of questions it answers, in the user’s language. once the descriptions said "use this for 'how much did i spend on x' questions" literally, the routing locked in.
the dashboard — cache & co.
the dashboard is a separate vite + react spa. design language is the same as this site — jetbrains mono, light theme, hairline rows, lowercase, no cards. the chat lives in a floating bubble in the lower-right corner; click it to open a popover anchored above the bubble. messages persist in localStorage so a refresh resumes the conversation. the n8n webhook receives a stable session id so the window-buffer memory keeps the same context across reloads.
clicking the chat bubble reveals the welcome state. four prompted suggestions — they double as a menu and a teaching device for what the agent can answer.
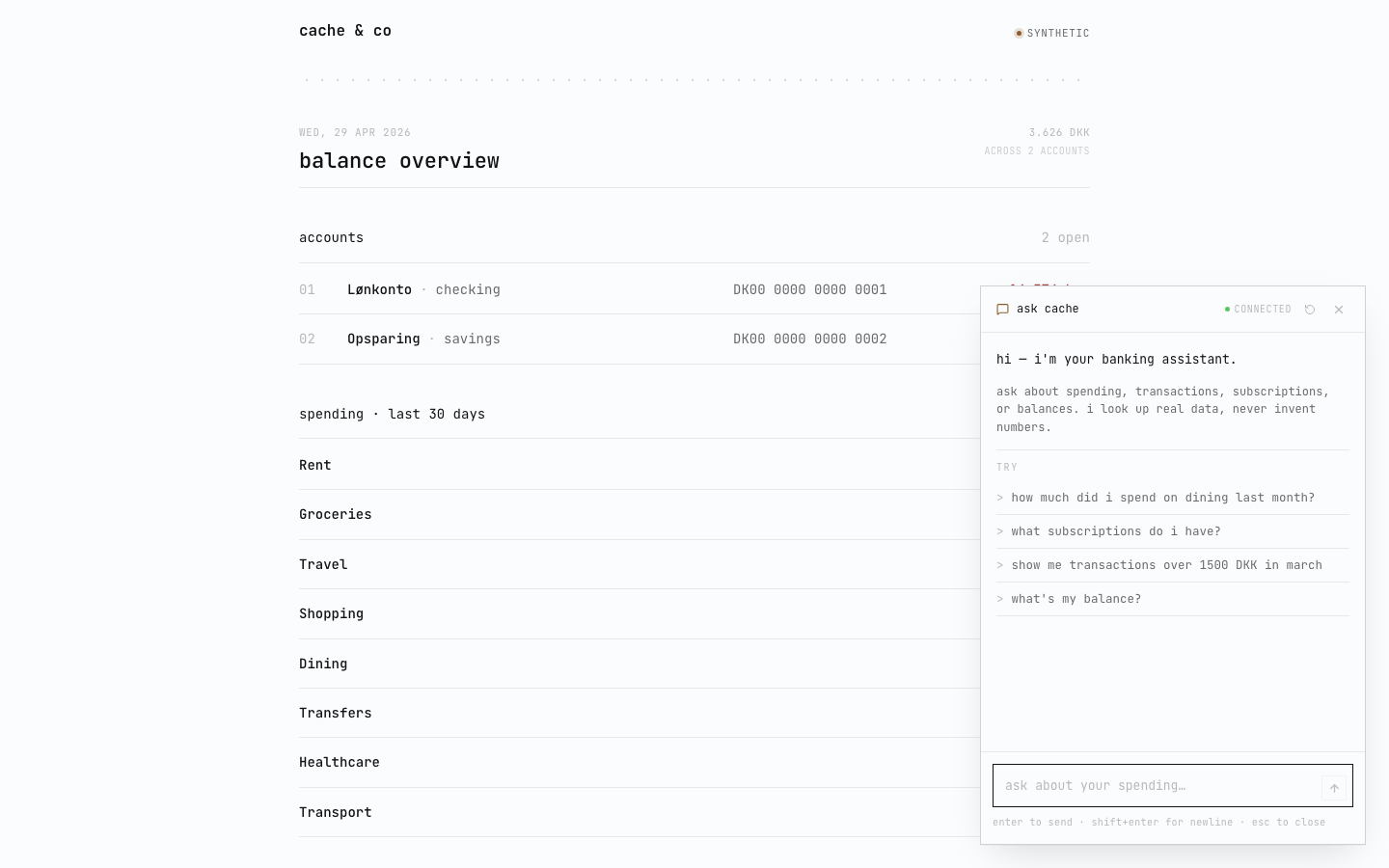
a real round-trip looks like this. user message at the top, the assistant’s reply below, both in the same hairline aesthetic as the rest of the ui.
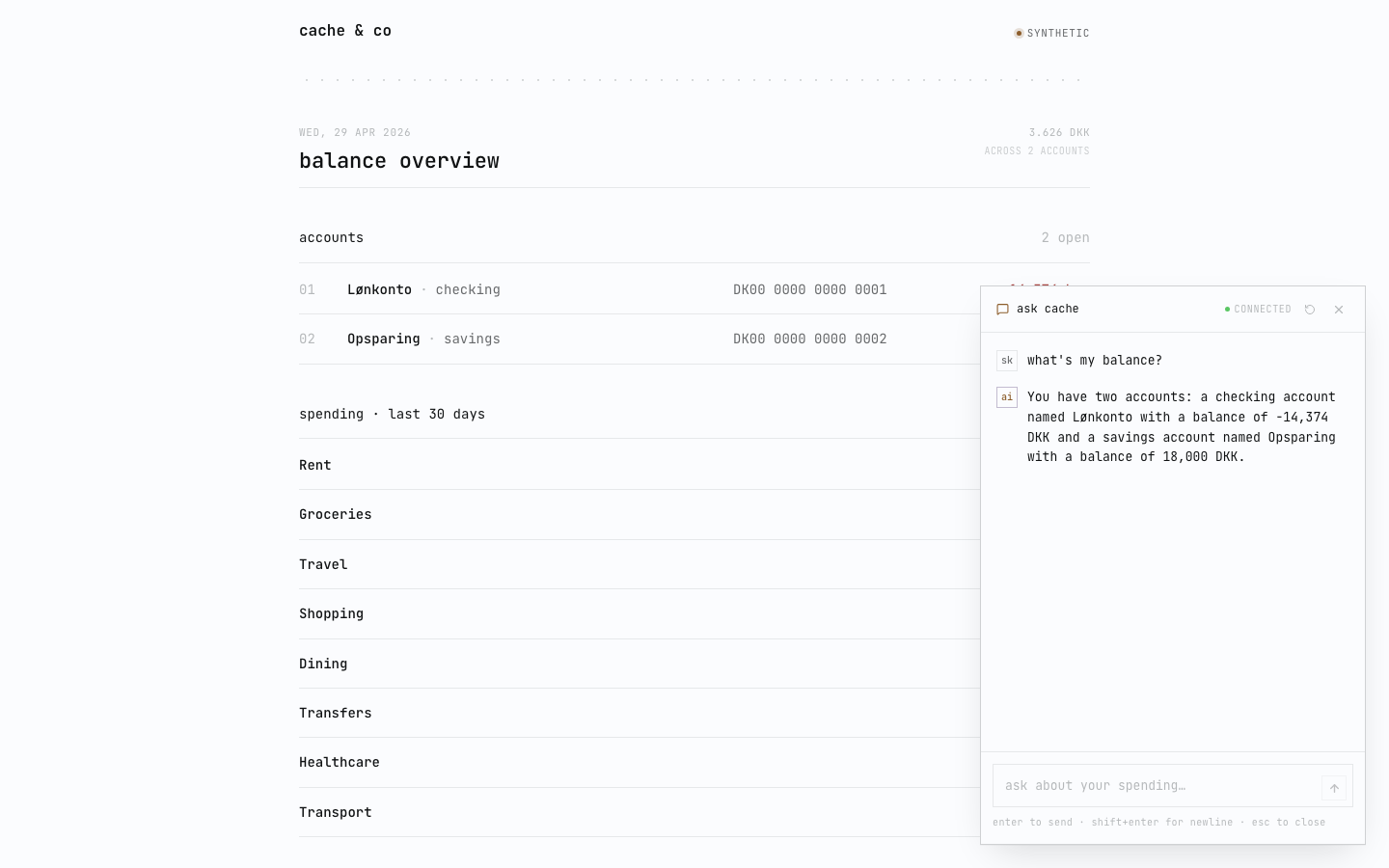
that’s the happy path. on a 7b cpu-only model the routing isn’t deterministic — the same loose phrasing (“how am i doing this month?”) sometimes calls aggregate_spending, sometimes list_accounts, sometimes both. tighter tool descriptions narrow the gap; they don’t pin it. on questions like the one above (“what’s my balance?”) the routing is reliable.
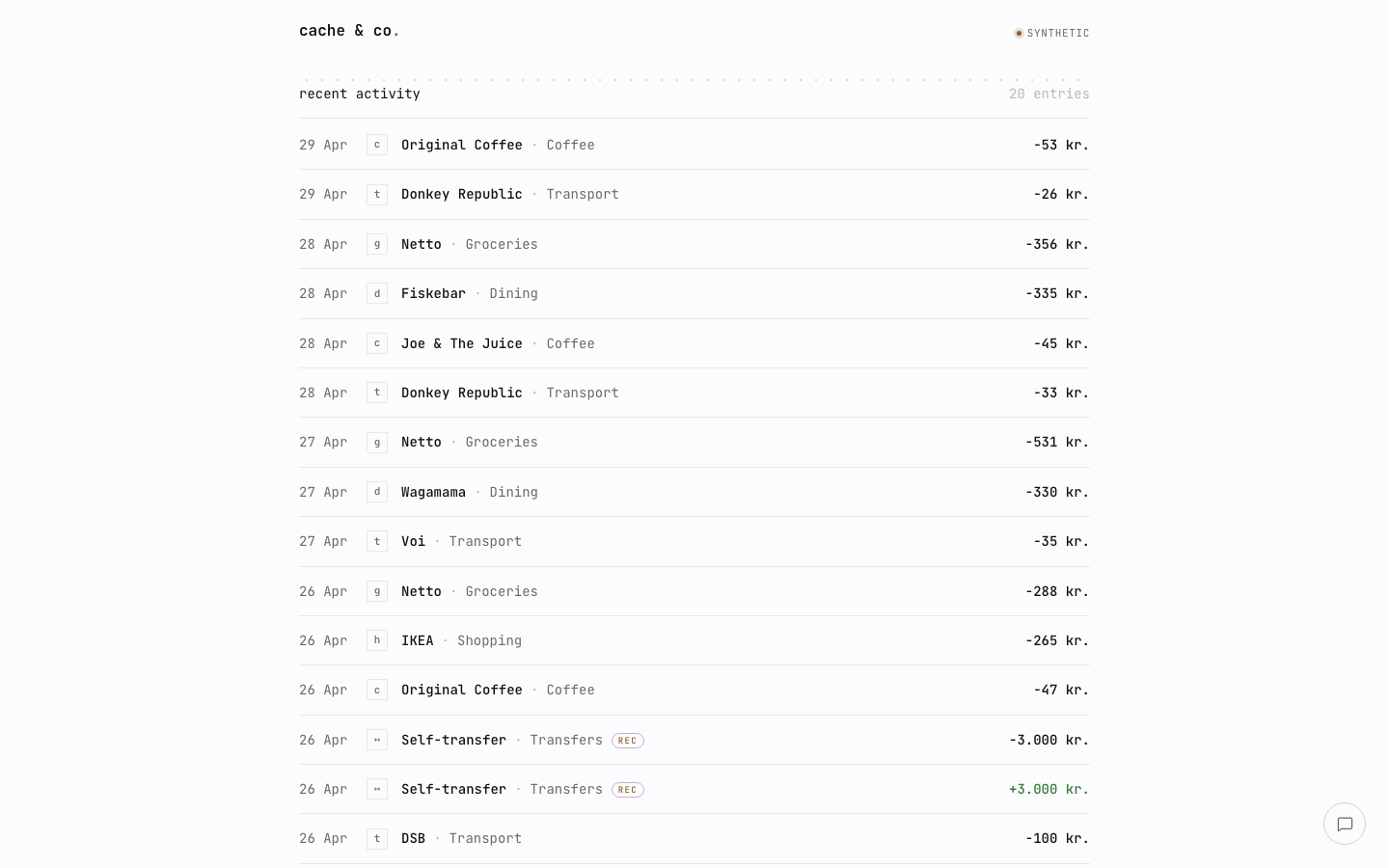
the recent-activity list lives further down the dashboard — same row pattern as everything else, with a single-character category glyph and tabular dkk amounts.
what worked, what didn’t
what worked:
- the helper-script pattern from the parent post carried over cleanly. n8n is the same lxc; the mock api will become a third lxc. the mental model holds.
- per-parameter
$fromAI()in the http request tool is the right primitive. you describe each query parameter once with a sentence the model understands, and the tool definition stays small. qwen2.5:7bwas the correct pick overllama3.1:8bfor tool-calling. cleaner json, better adherence to the parameter shape. it doesn’t fix all the routing issues, but it’s a strict improvement.
what didn’t:
- real-time chat is still out at this hardware tier. ~6 seconds for the cold model load, ~10-30 seconds for a tool call + reply on a warm model. it’s fine for “open the chat occasionally and ask a thing” — not fine for a typing-and-thinking conversational rhythm. the n8n executions log makes the cost visible: the same bank-chat workflow runs anywhere from 8 seconds to 5+ minutes depending on how many tools the agent strings together and whether the model loaded cold.
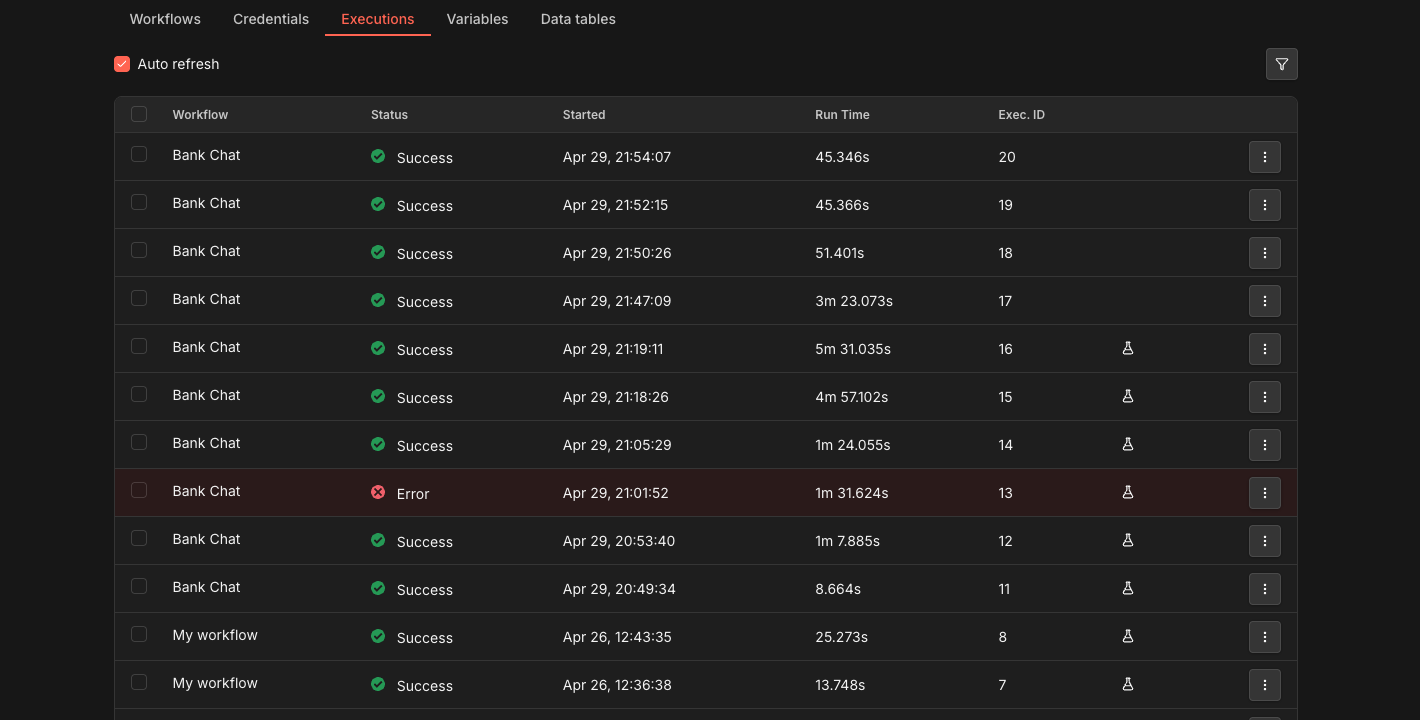
- tool selection is a probability distribution, not a function. on loose phrasings like “any unusual charges this week?” the model picks differently across runs. system prompts and sharper tool descriptions narrow the spread; they don’t collapse it.
- the fakery shows in the data shape. the synthetic generator produces clean periodicity — salary on the 25th, every month, exact same amount. real bank statements have that plus the noise. if the demo ever moves to real-feeling data, the generator needs jitter.
what’s next
three threads, in order of likelihood:
- move the mock api to a homelab lxc, behind caddy as
mock-bank.homelab.scalable.dk. gives the demo a stable url anyone on my lan can hit, and lets me retire the laptop process. - add a tool that detects unusual spending — “flag transactions that don’t fit my normal pattern”. forces the agent to do something the bank apis themselves don’t do, which is the actual reason to put an llm in front of this.
- structured output test against real questions — measure how often qwen returns valid tool-call json on a panel of 50 banking questions. ground-truth the “qwen is better at structured output than llama” claim from the parent post with numbers.
the homelab series — proxmox primer, lxc vs vm, unifi topology, caddy + dns-01 — is also still queued. they’re the plumbing layer underneath all of this.
a build log doesn’t have to end with a hero shot. for this one i’ll allow it: the chat works, the data is fake, the bank is cache & co., and the whole thing runs on a thinkcentre on a desk.